Use case at Edovo
The company I work for, Edovo, had the desire rearchitect an old content system and rebuild it using Elasticsearch. I had the pleasure of working on this project. This being my first time using Elasticsearch I learned a lot. This post goes into how we architected our cluster and lessons learned from it.
We decided to use one Elasticsearch index to hold our data. Each piece of content in our DB is represented as an Elasticsearch document (this also includes some joined table data compressed into one document). One major requirement was that we needed updates that occur to pieces of content in our DB to be reflected in the documents in Elasticsearch.
For this task we decided to use the AWS Elasticsearch service and communicate with it through API requests for version 7.8.
Architecture
For our index we decided to use 1 primary shard and 2 replica shards and scale up as needed. Index operations only go to the primary shard while search operations go to all 3 shards. We knew that we weren’t going to be indexing very much and having fast searches was important to us. Based on this primary and replica count, we needed at least 3 data nodes since a primary and replica shard can’t live on the same node.
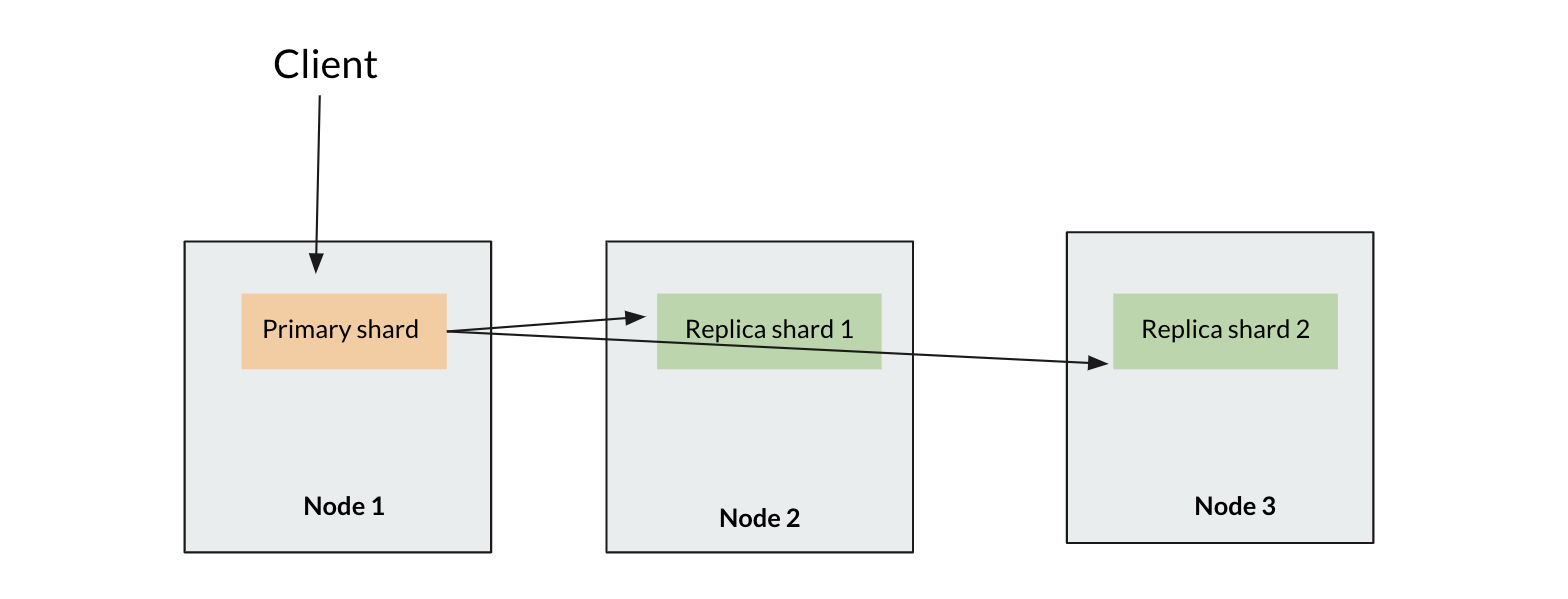 indexing operations
indexing operations
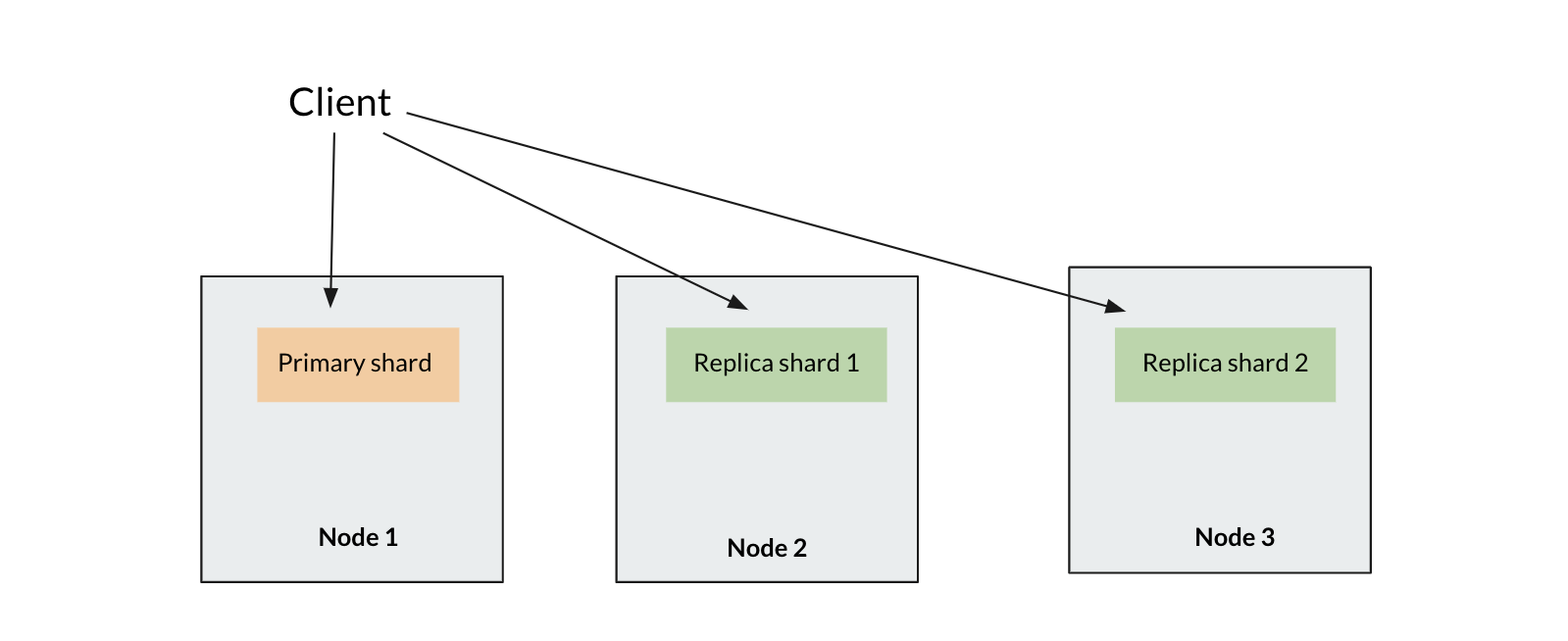 searching operations
searching operations
Our index was composed of documents from data in our DB and we bulk uploaded them to ES using their bulk API. With our volume of documents, we decided to bulk upload our documents in batches to avoid any timeouts.
The power from Elasticsearch is of course search. Elasticsearch has its own query DSL that
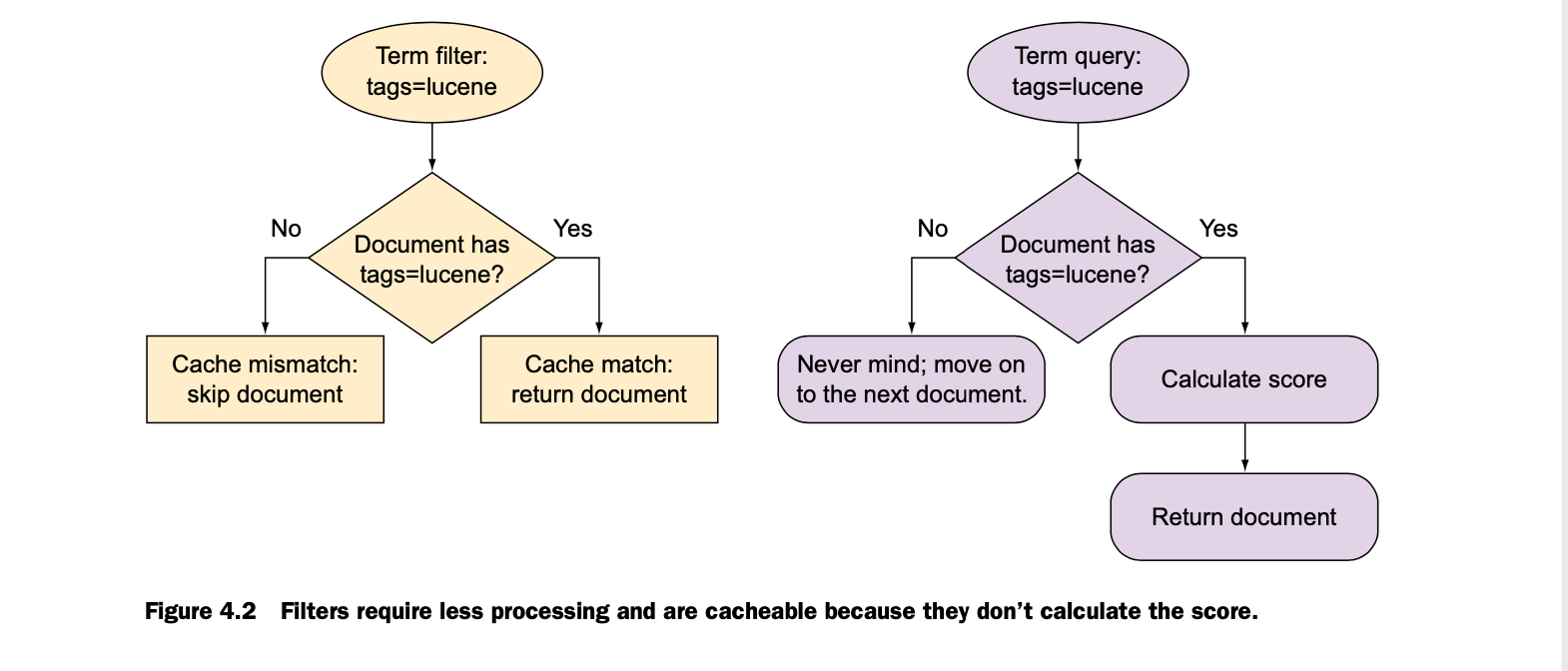
took a bit of time to learn, but has a lot of great functionality. The biggest lesson I learned from it is the difference between asking for a query vs. filter.
A query is best used if you would like ES to calculate the scores of documents which best match your search and send back documents with the highest score. This is
particularly useful for things like keyword search. But if you are not concerned about best matches and instead want ES to return documents that just match your request
(like a yes/no question) a filter is most optimal. It’s faster because it doesn’t calculate a score and it has the added benefit of caching the results so subsequent
requests will be faster. The Elasticsearch in Action book had a great diagram for this:
One of our main requirements was to trigger a document update when certain DB changes were made. This was best accomplished by adding an additional function call to update a document after our function call to make DB changes. ES has a nice feature where if you provide the API with an ES id and a new document it will overwrite the existing document. If no ES id is provided it will create a new document. More info about that can be found here. This provided a cleaner and simpler solution in our code rather than using the ES painless language found here
Additionally, we wanted zero downtime when creating a new index. In order to achieve this we followed a blue green deployment strategy. We took advantage of Elasticsearch index aliases. The alias would point to the current live index. When building a new index, after all documents are loaded into the new index and the documents are reachable we switch the alias to point to the new index. An added benefit to this technique is that it gave us the ability to rollback to previous (old) indices in case we needed to.
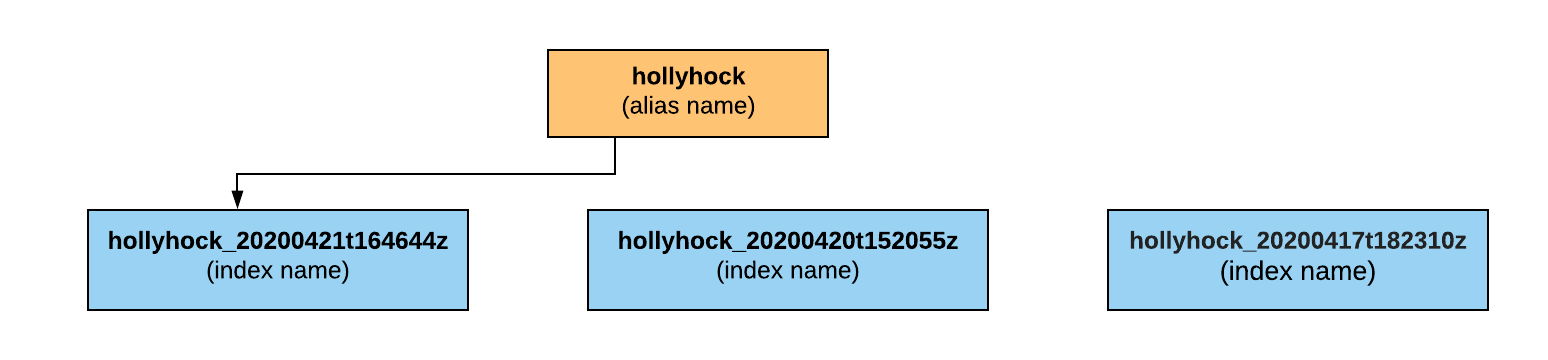 index architecture for zero downtime reindex
index architecture for zero downtime reindex
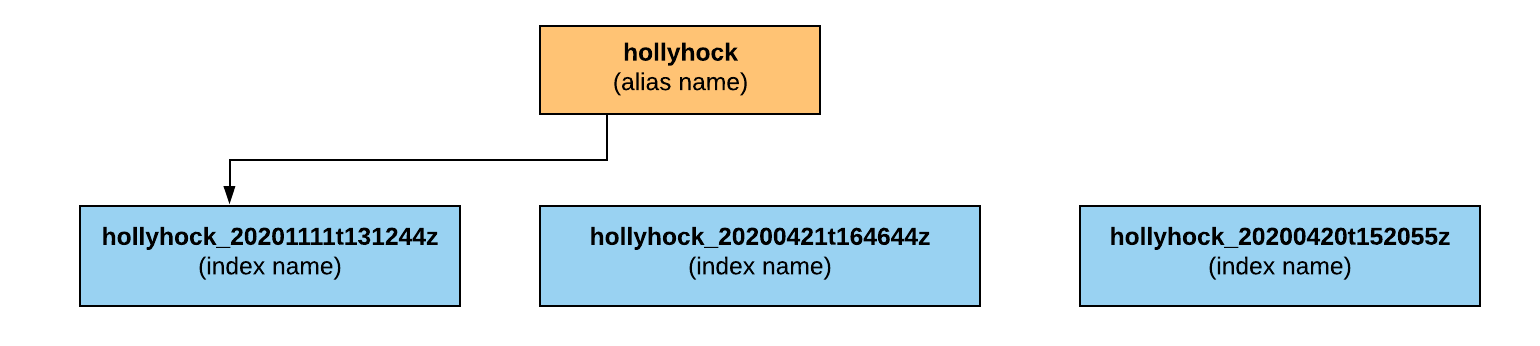 after a reindex the alias points to the newly built index and deletes old indices
after a reindex the alias points to the newly built index and deletes old indices
Code design
From a code perspective, it eventually became clear to breakout each API call
into a separate function and categorize those functions into different classes that represented index actions and document actions. This helped to keep in the line with
the single responsibility principle and smaller, more manageable classes. For each function we decided to a Result type architecture as found in some ML languages like
Haskell and Elm.
public Result<SuccessfulObject, String> apiCall() {
// code to make API request
}
This allowed us to have a much finer grained control over error handling and cleaner code. We could bubble up and display errors when wanted to instead of having try, catches in all our functions.
Testing
As far as testing, we decided to spin up an ES cluster locally and test our API functions against that cluster. The one downside of this was that we couldn’t test the error conditions very thoroughly, but it did allow us to have confidence that our API calls were successful.
Production lessons
Soon it became time to launch this system. We decided to increment up our load to the cluster. Although early on we starting seeing intermittent yellow cluster statuses throughout the week which was causing some API calls to timeout. After some guidance from AWS support, it became clear that the t2 instance sizes should not be used in production. So we decided to upgrade our instances to m5. With our load of about 700,000 requests per day to our cluster with a peak minute of around 1,000 requests we were able to have an average response time of about 42 ms, so our 3 node cluster was working great.
Conclusion
After spending about 8 months working with Elasticsearch I really enjoyed my time with it. The API is very easy to use and has a lot of flexibility. Additionally, once we started to onboard users to our new system I had the chance to see the power of the load it could handle and the various ways we could scale. That being said it’s not a trivial piece of technology and takes time to learn. But if the use case is right it’s well worth the investment!