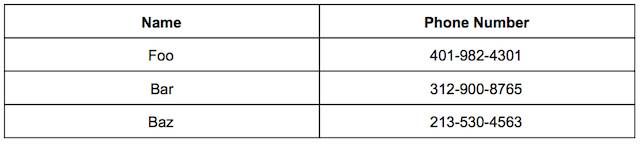
Hash functions can be particularly useful for searching through a database with a large amount of data. For example, lets say you have a very large table of name and phone numbers like this
…
Given a name if you wanted to find the corresponding phone number you would have to look through each name in the column of the database to see if it matches the one you’re looking for. This query is O(N) because you have to look through each name in the column.
There is a faster way using hash functions. What if we could map the names of the database column to an index in an array. And the contents of the array at that index is the corresponding phone number. Then accessing an index from an array is constant O(1).
Lets say our array has a length of 13 (meaning the indicies would run from 0 to 12). Here’s one way it could be done.
Step 1:
We can find the sum of ASCII values of each character in the string.
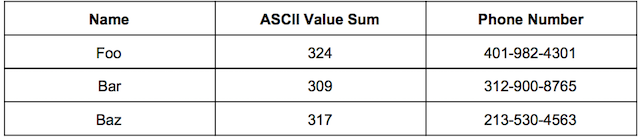
Since we want to map the name to an index in the array we can mod the ASCII Value sum by the length of the array, in our case 13.
Giving us this new table
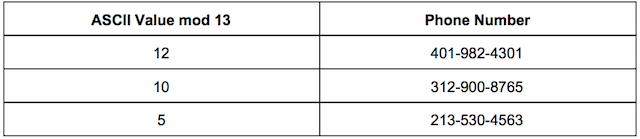
So our hash function is defined as h(k) = k mod 13 where k is equal to the ASCII value sum.
This data structure is a called a hash table. The keys are indexes and the values are stored in the corresponding index. Note that is different from an array by the fact that an array is populated consecutively. Ex: if had an array with [401-982-4301, 312-900-8765, 213-530-4563] The corresponding indexes would be [0, 1, 2].
So now we have populated our hash table. To find Baz’s phone number we no longer have to go through each row in the table. We can run Baz through our hash function which will output a value of 12 so we know that Baz’s phone number lives at index 12.
But what if we now had a table that looked like this
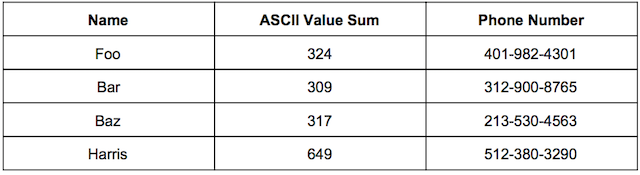
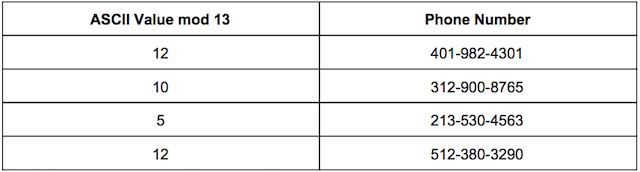
Now both Foo and Harris have the same hash value. So when we’re populating our hash table we get something called a collision - meaning two keys have the same hash value. There are a few clever ways to get around this
Linked List
We could create a linked list of values
This is what our hash table would look like
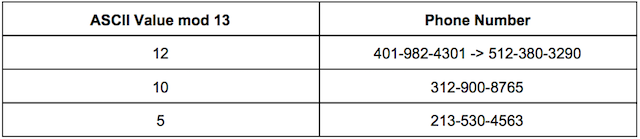
And when we run our query we would get back a list of all the values (which would still be faster than running a regular serach query).
Another Hash Function
When we’re populating the hash table and we realize that 12 already has a value stored into we can run “Harris” through another hash function and keep doing that until there is an open index. The only problem with this method is that lookups can become complex.
There are definitely benefits to using hash functions for database lookups, but they are not always useful. It does take time and space to populate a hash table. The most benefit will come when you’re doing lookups frequently.